We created this tool for users that need to work with CSV file.
Uploader works over CSV file with command to be done with the entity. Entity is API resource, like assets, markers, campaigns, users, etc. It’s impossible to manipulate with different entities in one CSV file. All the calls to uploader looks like this: POST https://api.bear2b.com/tools/uploader.ex.php
Parameters (to be send over POST request with ‘multipart/form-data’ content type):
| entity | Which entity will be changed by the Uploader. E.g. users, assets, markers, campaigns, etc. |
|---|---|
| csvfile | CSV file to be processed or ZIP archive with the following: CSV file, pages.pdf, res/ folder |
| bgrs | 1-asynchronous processing; 0-synchronous |
| encoding | CSV file encoding. E.g. UTF-8, ISO-8859-1, ISO-8859-2, etc. |
| show_progress | Display progress of CSV processing (1 – display progress; 0 – doesn’t) |
| campaign_id | If pages.pdf provided, markers will be created in this campaign, otherwise – in new one |
| get_content | This parameter works only if show_progress==1. If =1 Return content of the processed CSV in the response body, otherwise result uploaded to the server for 1 month and link to this file returned in the response content |
Each CSV file have 3 system fields (res, op, id). All other field are specific to each type of entity. Refer to appropriate API call’s doc for more details.
CSV records with empty op field are IGNORED.
System fields:
| field | description |
|---|---|
| res | this field will receive result of each row processing. Expected result following an upload is ‘OK’ |
| op | ‘c’ – create; ‘u’ – update; ‘d’ – delete. Note that id has to be provided for u & d only. For ‘c’ it should be empty |
| id | entity ID that will be changed in case of update (op == ‘u’) or deletion (op == ‘d’) |
Example of CSV file:
res;op;id;name;description;is_active
;c;;Campagne test API - P29;Test API Bear;1
;c;;Campagne test API - P23;(vidéo couverture);1
;c;;Test smartphone;;1
Separator symbol in CSV file can be comma (,) or semicolon (;)
The Uploader gets provided CSV file and process it line by line. Each line become API call under current user credentials with parameters names from the column name and values from the current line. Result of the call placed to “res” cell. You can see this on the scheme below: 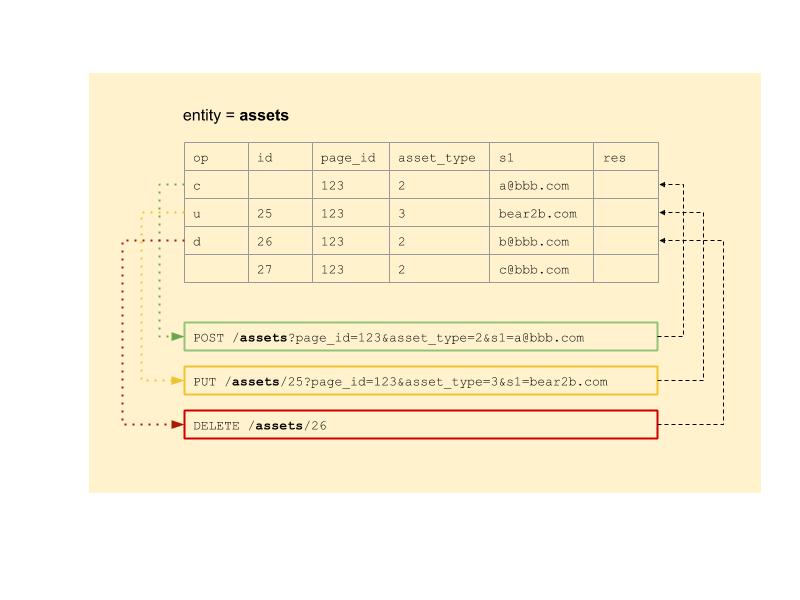
Synchronous processing
When all the rows of the CSV file processed, uploader returns csv file with processing results (with the same name as original file + ‘res.csv’ at the end). Each processed like has ‘OK’ in the ‘res’ column in case of success or error description in case of errors. Uploader also returns ids of newly created objects. It let us use CSV file from the response for further modifications.
Asynchronous processing
If bgrs parameter set to 1, Uploader goes to background and response with “bgrsID – background request ID” (e.g. a8fa2aa2e79e196eeeb2cd65b53abca4). You can now check status of the request by calling /bgrs/https://apidev.bear2b.com/bgrs/a8fa2aa2e79e196eeeb2cd65b53abca4
Response can look like this (all possible statuses are here):
[{
"id": "1",
"rid": "a8fa2aa2e79e196eeeb2cd65b53abca4",
"user_id": "1",
"name": "uploader",
"created_dt": "2017-03-28 13:44:29",
"status_id": "2",
"status_name": "in progress",
"progress": "10.00",
"finished_dt": "",
"result": ""
}]
To get details (progress of the request processing): https://apidev.bear2b.com/bgrs/a8fa2aa2e79e196eeeb2cd65b53abca4/details
[{
"id": "1",
"rid": "a8fa2aa2e79e196eeeb2cd65b53abca4",
"dt": "2017-03-28 13:44:29",
"details": "Start processing..."
},
{
"id": "2",
"rid": "a8fa2aa2e79e196eeeb2cd65b53abca4",
"dt": "2017-03-28 13:44:29",
"details": "Extracting zip file..."
},
{
"id": "3",
"rid": "a8fa2aa2e79e196eeeb2cd65b53abca4",
"dt": "2017-03-28 13:44:29",
"details": "Extracting zip file completed."
},
...
,{
"id": "20",
"rid": "a8fa2aa2e79e196eeeb2cd65b53abca4",
"dt": "2017-03-28 13:44:38",
"details": "Line: 4 done. Result: 200. OK"
},
{
"id": "21",
"rid": "a8fa2aa2e79e196eeeb2cd65b53abca4",
"dt": "2017-03-28 13:44:38",
"details": "done"
}]
When request finished it looks like this: https://apidev.bear2b.com/bgrs/a8fa2aa2e79e196eeeb2cd65b53abca4
[{
"id": "1",
"rid": "a8fa2aa2e79e196eeeb2cd65b53abca4",
"user_id": "1",
"name": "uploader",
"created_dt": "2017-03-28 13:44:29",
"status_id": "4",
"status_name": "finished",
"progress": "100.00",
"finished_dt": "2017-03-28 13:44:38",
"result": "media/keep1d.add-on.zip.result.csv"
}]
ZIP file processing
Uploader can work with archive contains csv file, pdf file (optional) and /res folder (optional). In case if pdf file provided, new markers will be created from the pages of this pdf file. Names of the newly created markers will are “page 001”, “page 002”, etc.
In case of markers created from pdf file and for entity=assets, CSV file can point to marker ids as page number of pdf file. E.g. 1,2,3,5,etc. Uploader will match pdf page with real marker ID automatically.
Res folder
Csv file can have links to the resources located in res folder like here:
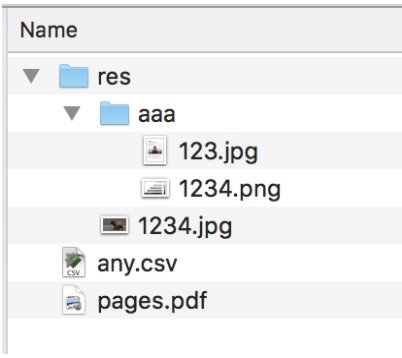
Links inside CSV can look like ‘res/aaa/1234.png’ In this case this folder will be uploaded to BEAR file storage as is and res/* links in newly created assets will have links to files inside this folder in BEAR file storage.